回归分析法计算公式
回归分析法计算公式
在统计分析领域中,回归分析法是一种常用于探索因变量和自变量之间关系的统计方法。本文将详细介绍回归分析的基本概念、类型、应用场景以及具体的计算公式。
一、回归分析的基本概念
回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(特征)之间的统计关系。这通常是在科学研究、经济预测和统计分析中用于找出数据中的因果关系的一种常用方法。简单来说,它利用现有的数据进行训练,寻找一种最有可能代表因变量与自变量关系的模型,通过此模型对新的数据作出相应的预测。
二、回归分析的类型
回归分析主要分为线性回归和非线性回归。线性回归是最为常见的一种回归分析方法,其自变量与因变量之间的关系是线性的。而非线性回归则是指自变量与因变量之间的关系不是线性的。此外,还有多项式回归、逻辑回归等多种类型。
三、回归分析的公式
在回归分析中,最常用的是线性回归模型。其基本公式为:y = β0 + β1x1 + β2x2 + ... + ε。
这个公式中的符号表示如下:
y: 被称为因变量(或称依赖变量、结果变量等),代表我们需要研究和预测的目标。
β0: 常数项,也称为截距项,表示当所有自变量都为0时,因变量的预测值。
β1, β2, ...: 称为回归系数,表示自变量对因变量的影响程度。具体来说,每个自变量的系数都表示在保持其他自变量不变的情况下,该自变量变化一个单位时,因变量的平均变化量。
x1, x2, ...: 称为自变量(或特征变量),是影响因变量的潜在因素。
ε: 误差项,表示模型未能解释的部分。它反映了模型预测的准确性以及数据中的随机性。
四、回归分析的应用场景
回归分析广泛应用于各种领域的研究中,例如经济预测、医学研究、气象预报等。它可以有效地探索和分析多个自变量与因变量之间的复杂关系,揭示各种现象的因果关系。此外,回归分析还能帮助我们理解数据的模式和趋势,为决策提供科学的依据。
五、注意事项
在使用回归分析时,需要注意以下几点:
- 自变量的选择:要谨慎选择影响因变量的潜在因素,确保选用的自变量对因变量的预测有实质性贡献。
- 多重共线性:注意检查自变量之间是否存在相关性或完全相关的关系。如果出现这一问题,可能对回归结果的解释产生影响。
- 异方差性:检查因变量的误差项是否具有恒定的方差。如果存在异方差性,可能需要采取相应的措施进行修正。
- 数据的质量和数量:确保用于分析的数据具有较高的质量和数量,以获得更准确的回归结果。
六、总结
本文介绍了回归分析的基本概念、类型和具体公式,并通过简单易懂的例子让读者了解了它的实际应用和意义。回归分析作为常用的数据分析工具,具有广泛的用途和研究价值。
通过掌握好以上的概念与知识点,并勤加实践使用在案例中,相信读者能更好地理解和应用回归分析法。同时,也需要注意在使用过程中遵循科学的研究方法和严谨的统计原则。





















 查看未读消息
查看未读消息 查看最新消息
查看最新消息









 分享
分享
 复制
复制 全选
全选 总结
总结 解释一下
解释一下 延展问题
延展问题 自由提问
自由提问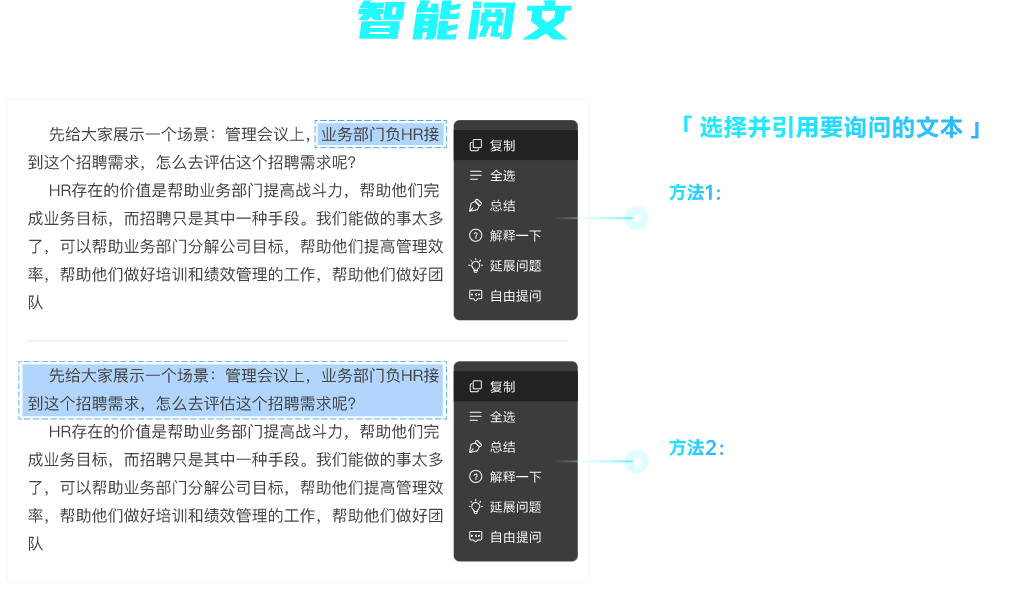













 复制
复制 分享
分享