信息增益怎么算
信息增益是决策树算法中一个重要的概念,它用来衡量数据集在某个特征上的纯度提升程度。在机器学习和数据挖掘中,信息增益常用于决策树的构建过程中,通过计算不同特征的信息增益来选择最优的划分特征,从而构建出更加准确和高效的决策树模型。
一、信息熵
在理解信息增益之前,我们需要先了解信息熵的概念。信息熵是一种衡量信息不确定性的指标,表示的是数据的混乱程度。简单来说,如果一个事件的结果具有很高的不确定性,那么它的信息熵就高;反之,如果事件的结果确定性高,那么它的信息熵就低。
在计算信息熵时,我们通常使用以下公式:
Entropy = -sum(P(i) log2(P(i)))
其中,P(i)表示第i个类别的概率,log2表示以2为底的对数运算。通过计算整个数据集的信息熵,我们可以得到数据集的初始混乱程度。
二、信息增益的计算
信息增益是用于衡量使用某个特征进行划分后,数据集的混乱程度减少的度量。它等于划分前数据集的信息熵与划分后各个子集的信息熵加权求和之差。
具体计算步骤如下:
- 计算整个数据集的信息熵。
- 对每一个特征进行遍历,假设当前特征有m个可能的取值,根据该特征将数据集划分为m个子集。
- 对于每一个子集,计算其包含的样本数以及各类别在子集中的概率。
- 根据子集的样本数占原数据集的比例作为权重,计算每个子集的信息熵。
- 计算按照当前特征划分后的总信息量(各个子集信息熵乘以子集样本数占原数据集的比例)。
- 信息增益等于原数据集的信息熵减去按当前特征划分后的总信息量。
通过比较不同特征的信息增益,我们可以选择信息增益最大的特征作为划分依据,从而构建出更加高效和准确的决策树模型。
三、信息增益的应用
信息增益在决策树算法中有着广泛的应用。在构建决策树的过程中,我们通常需要选择一个最优的特征进行数据集的划分。通过计算每个特征的信息增益,我们可以选择信息增益最大的特征作为根节点或内部节点的划分依据。
在决策树的每个节点上,我们都可以通过计算不同特征的信息增益来选择最优的划分方式,从而构建出更加高效和准确的决策树模型。同时,信息增益还可以用于评估特征的重要性程度,为后续的特征选择和模型优化提供参考。
四、总结
信息增益是决策树算法中一个重要的概念,它用于衡量数据集在某个特征上的纯度提升程度。通过计算不同特征的信息增益,我们可以选择最优的划分特征来构建决策树模型。同时,信息增益还可以用于评估特征的重要性程度,为后续的特征选择和模型优化提供参考。在机器学习和数据挖掘中,信息增益是一个非常有用的工具,可以帮助我们更好地理解和利用数据。





















 查看未读消息
查看未读消息 查看最新消息
查看最新消息









 分享
分享
 复制
复制 全选
全选 总结
总结 解释一下
解释一下 延展问题
延展问题 自由提问
自由提问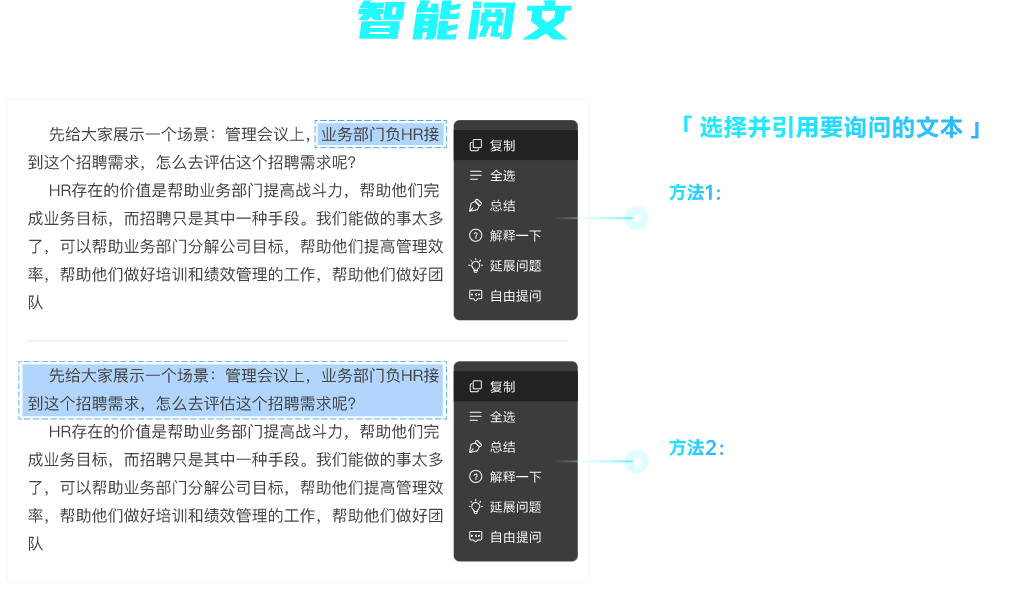













 复制
复制 分享
分享