rpa和爬虫的区别
RPA与爬虫的区别
随着数字化进程的深入,企业和个人越来越依赖数据的收集与处理。在这一背景下,两大自动化技术——RPA(Robotic Process Automation)和爬虫(网络爬虫),各自凭借其独特的技术特点与优势,成为了实现数据自动化的重要工具。然而,尽管两者都致力于实现数据的自动化获取与处理,但它们在应用场景、工作原理及伦理道德等方面存在显著差异。
一、应用场景的区别
RPA主要应用于企业内部流程的自动化。它通过模拟人类在计算机上的操作,执行重复性、规则性的任务,如数据录入、发送邮件、管理日程等。这些任务通常涉及企业内部的业务流程,如财务结算、人事管理、订单处理等。RPA可以大大提高企业内部的工作效率,降低人力成本。
相比之下,爬虫则更多地应用于网络数据的收集与分析。它通过网络请求技术,如HTTP/HTTPS等,获取网页内容,然后通过解析技术提取出需要的数据。这些数据可能用于市场分析、舆情监测、竞争对手分析等场景。
二、工作原理的区别
RPA的工作原理主要是模拟人的操作行为。它通过预设的规则和流程,自动执行一系列操作,如点击、输入、复制粘贴等。这些操作无需人工编写代码,只需通过图形化界面进行配置即可实现。RPA强调的是对已有系统和流程的优化与简化。
而爬虫则是通过网络爬取技术来收集数据。它通过发送网络请求到目标网页的服务器,获取网页的HTML代码,然后通过解析这些HTML代码提取出需要的数据。爬虫工作过程中需要考虑的问题包括但不限于:如何识别目标网页、如何提取有效信息、如何处理反爬虫策略等。
三、伦理道德的考量
在伦理道德方面,RPA由于其工作在已存在的系统与流程内,其操作行为大多在合法合规的范围内进行,故而引发的伦理道德问题相对较少。然而,在使用RPA时仍需注意保护用户隐私和数据安全。
而爬虫在数据收集过程中可能会涉及到隐私权和数据保护的问题。如果未经许可就大量爬取网站数据,可能会侵犯他人的隐私权和数据保护权。因此,在使用爬虫进行数据收集时,必须遵守相关法律法规和网站规定,尊重他人的隐私和数据权利。
四、技术发展趋势
随着人工智能技术的发展,RPA和爬虫都将迎来更大的发展空间。RPA将更加深入地应用于企业内部的业务流程自动化,提高企业的运营效率。而爬虫则将在大数据领域发挥更大作用,帮助企业和个人从海量的网络信息中提取出有价值的数据。
总的来说,RPA和爬虫都是实现数据自动化的重要工具,但它们在应用场景、工作原理和伦理道德等方面存在显著差异。了解这些差异有助于我们更好地理解这两大技术在不同场景中的应用与价值。在未来,随着技术的不断进步,我们有理由相信RPA和爬虫将在更多领域发挥更大的作用。





















 查看未读消息
查看未读消息 查看最新消息
查看最新消息









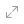
 分享
分享
 复制
复制 全选
全选 总结
总结 解释一下
解释一下 延展问题
延展问题 自由提问
自由提问













 复制
复制 分享
分享