聚类分析方法
聚类分析方法:数据处理的重要手段
一、引言
在当今的大数据时代,如何有效地处理和分析海量数据成为了一个重要的研究课题。聚类分析方法作为一种无监督学习的数据处理手段,能够在没有标签的情况下,将数据集分成由类似的数据组成的群组,揭示数据的内在规律和结构。本文将详细介绍聚类分析方法的基本原理、应用领域以及其重要性。
二、聚类分析方法的基本原理
聚类分析是一种将数据集分为几个不同的组或“簇”的统计分析方法。这些组内的数据点具有相似性,而不同组之间的数据点则具有较大的差异性。聚类分析的主要目标是在没有先验知识的情况下,通过计算数据点之间的相似性或距离,将数据划分为具有特定性质的群组。
聚类分析的基本步骤包括:数据预处理、特征提取、相似性度量、聚类算法实施以及结果评估。其中,聚类算法是聚类分析的核心,常见的聚类算法包括K-means聚类、层次聚类、DBSCAN聚类等。
三、聚类分析方法的应用领域
聚类分析方法在各个领域都有广泛的应用。在市场研究领域,聚类分析可以帮助企业了解消费者的需求和偏好,从而制定更加精准的市场策略。在生物信息学领域,聚类分析可以用于基因表达数据的分析,揭示基因之间的相互关系和生物过程的规律。在图像处理领域,聚类分析可以用于图像分割和目标识别等任务。
四、聚类分析方法的实施步骤
1. 数据预处理:包括数据清洗、缺失值处理、异常值处理、数据标准化等步骤,以确保数据的准确性和可靠性。
2. 特征提取:根据研究目的和数据特点,选择合适的特征进行提取,降低数据的维度。
3. 相似性度量:选择合适的相似性度量方法,如欧氏距离、余弦相似度等,计算数据点之间的相似性。
4. 聚类算法实施:选择合适的聚类算法,如K-means聚类、层次聚类、DBSCAN聚类等,对数据进行聚类。
5. 结果评估:通过绘制簇内散点图、计算簇内距离等方式,对聚类结果进行评估和解释。
五、聚类分析方法的重要性
聚类分析方法在数据处理和分析中具有重要的意义。首先,它可以帮助我们更好地理解数据的内在规律和结构,发现数据中的潜在模式和关系。其次,聚类分析可以用于数据降维,将高维度的数据转化为低维度的数据,便于我们进行进一步的分析和处理。最后,聚类分析还可以用于预测和决策支持,为决策者提供有力的支持。
六、结论
总之,聚类分析方法是一种重要的数据处理手段,可以帮助我们更好地理解数据的内在规律和结构,发现数据中的潜在模式和关系。在当今的大数据时代,聚类分析方法的应用前景将更加广阔。未来,随着技术的不断发展和进步,聚类分析方法将在更多领域得到应用,为人类的发展和进步做出更大的贡献。





















 查看未读消息
查看未读消息 查看最新消息
查看最新消息









 分享
分享
 复制
复制 全选
全选 总结
总结 解释一下
解释一下 延展问题
延展问题 自由提问
自由提问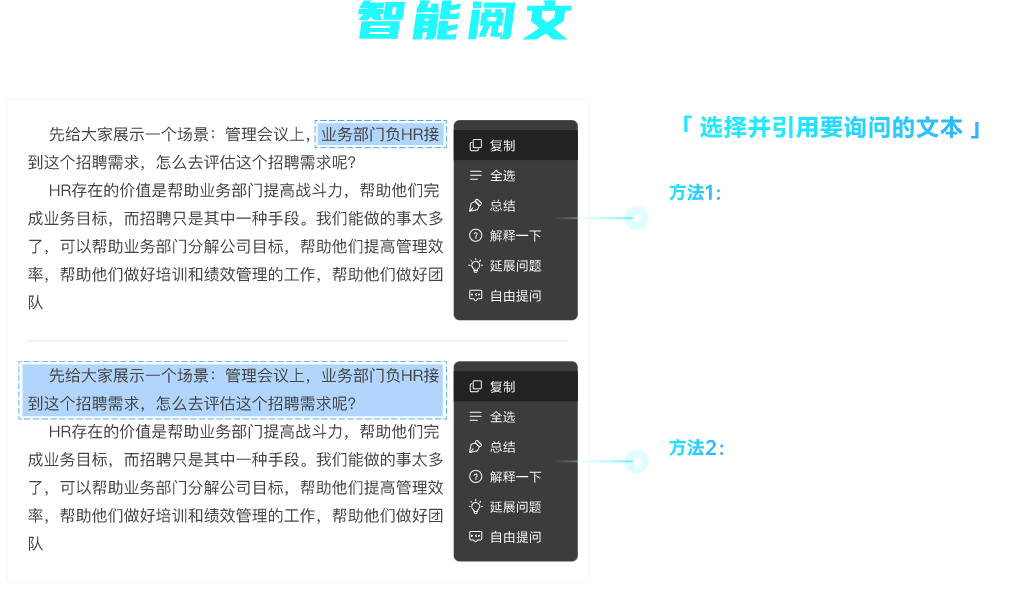













 复制
复制 分享
分享